
Things I want to do
Run SD3.5-medium (stable-diffusion-3.5-medium) from the command line using stable-diffusion.cpp.
It’s rumored to be fast and of good quality.
It can run on both AMD GPUs and CPUs.
environment setup
stable-diffusion.cpp
Download the appropriate Zip file for your environment from the following page.
If you want to run it on an AMD GPU, you need something with ‘vulkan’ or ‘rocm’ in its name.
(Basically, Vulkan should be fine. ROCM will likely have limitations on which GPUs can be used.)
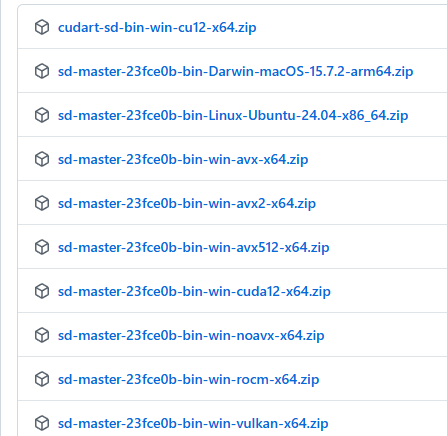
This applies to NVidia GPUs with ‘CUDA’ in their name.
AVX512, AVX2, AVX, and NOAVX are CPU-based. Please check which AVX version is compatible with your CPU and download it. (I was mistaken, but it seems AMD CPUs can also use AVX. It’s easiest to ask an AI which version is compatible.)
Once you’ve extracted the downloaded file to a folder of your choice, you’re ready to go.
Model
Please download one model from the following page. (The higher the number after Q, the better the performance and the longer the generation time.)

Next, download one of the t5xxl_XXXXX.safetensors files, along with clip_g.safetensors and clip_l.safetensors (a total of three files) from the following page.

Next, download diffusion_pytorch_model.safetensors from the following page. Please note that you will need to log in to huggingface and agree to the terms of use to download it. (After logging in and going to the model card tab, a UI for agreeing to the terms will be displayed.)

execution
Launch the command line and navigate to the folder where you extracted stable-diffusion.cpp.
Execute the following command. (Replace the model path with the path to the model you are using.)
sd-cli.exe --diffusion-model ModelPath --clip_l clip_l.safetensorsPath--vae diffusion_pytorch_model.safetensorsPath --clip_g clip_g.safetensorsPath --t5xxl t5xxl_XXXX.safetensorsのパス -H 512 -W 512 -p "a lovely cat" --cfg-scale 4.5 --sampling-method euler -v --clip-on-cpu
If a cat image is generated in the folder where you executed the command, it was successful.

Options (arguments)
The options are summarized on the following page.
Only the most commonly used basic ones are listed below.
| -m | Model path |
| -p | prompt |
| -s | Seed value Specify -1 to generate randomly. Please note that if you do not specify a format, the same image will be generated every time. |
-H | Image height |
| -IN | Image width |
--foot | VAE path |
--steps | Step. Initial value: 20 Note that for some models, a lower number may be better. (The official example from Qwen Image was 50.) |
Execution speed
The image generation speed is as follows: (This does not include model loading time or time after iteration.)
| Model | 生成時間(s) |
| stable-diffusion(Vulkan) | 36 |
| Qwen Image(Vulkan) | 623 |
| SD3.5-medium(Vulcan) | 56 |
In my personal opinion, as rumored, the image quality is higher than StableDiffusion, and it seems to have a better balance than the two models I compared it to.

コメント