
やりたいこと
stable-diffusion.cppを使用してコマンドラインからSD3.5-midium(stable-diffusion-3.5-medium)を実行します。
早くて質がいいと噂です。
AMDの GPUでも CPUでも実行可能です。
環境構築
stable-diffusion.cpp
以下のページから自分の環境にあったZipファイルをダウンロードします。
AMDのGPUで動かしたい場合はvulkanとつくものかrocmとつくものです。
(基本的にはvulkanでいいと思います。rocmはどうするGPUが限られるはずです。)
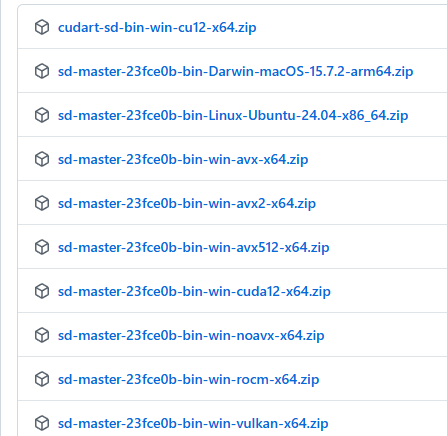
NVidiaのGPUはcudaが付くものが対象です。
avx512,avx2,avx,noavxはCPU動作です。お使いのCPUで使用できるavxのバージョンを調べてダウンロードしてください。(私は誤解していたのですがAMDのCPUもAVX使えるようです。どのバージョンが使用できるかはAIに聞いちゃうのが楽です。)
対象のダウンロードしたファイルを任意のフォルダに解凍したら準備完了です。
モデル
以下のページから一つモデルをダウンロードしてください。(Qの後の数字が大きいほど性能が高く、生成に時間がかかります。)

続けて以下のページからt5xxl_XXXXX.safetensorsのうち一つとclip_g.safetensors、clip_l.safetensors(計三つ)をダウンロードします。

続けて以下のページからdiffusion_pytorch_model.safetensorsをダウンロードします。ダウンロードにはhuggingfaceにログインして使用条件に同意する必要があるのでご注意ください。(ログインしてmodel cardのタブに移動すると同意するためのUIが表示されます)

実行
コマンドラインを起動してstable-diffusion.cppを解凍したフォルダに移動します。
以下のコマンドを実行します。(モデルパス部分は使用するmodelのパスに置き換えてください)
sd-cli.exe --diffusion-model モデルパス --clip_l clip_l.safetensorsのパス --vae diffusion_pytorch_model.safetensorsのパス --clip_g clip_g.safetensorsのパス --t5xxl t5xxl_XXXX.safetensorsのパス -H 512 -W 512 -p "a lovely cat" --cfg-scale 4.5 --sampling-method euler -v --clip-on-cpu
実行したフォルダに猫の画像が生成されれば成功です。

オプション(引数)
オプションは以下のページにまとめられています。
よく使われる基本的なものだけ以下に記載します。
| -m | モデルのパス |
| -p | プロンプト |
| -s | シード値 ランダムで生成するには-1を指定する。 指定しない場合、毎回同じ画像が生成されるため注意。 |
-H | 画像高さ |
| -W | 画像幅 |
--vae | VAEのパス |
--steps | ステップ。初期値20 モデルによっては少ない数字の方がいいので注意。 (Qwen Imageの公式の例では50でした。) |
実行速度
画像の生成速度は以下の通りです。(モデルのロード時間やイテレーション後の時間は含んでいません)
| モデル | 生成時間(s) |
| stable-diffusion(Vulkan) | 36 |
| Qwen Image(Vulkan) | 623 |
| SD3.5-midium(Vulkan) | 56 |
個人的な感想ですが、噂通りStableDiffusionよりも画像の質が高く、比較した二つのモデルよりもバランスに優れているように感じました。

コメント