
やりたいこと
llama.cppを使用してローカルでLLM(チャットAI)を実行します。
この記事ではgoogleのローカル向けのモデルであるgemmaを使用します。
AMDのGPUでもGPUのない環境(CPU)でも実行可能です。
環境構築
llama.cpp
以下のページから自分の環境にあったZipファイルをダウンロードします。
WindowsでAMDのGPU(もしくはGPUが乗っていない)で動かしたい場合はvulkanむけのパッケージで動作します。
NvidiaのGPUを使用する場合、CUDAむけのパッケージで動作します。
上記のバージョンで動作しない場合はCPUむけのパッケージを使用します。
対象のダウンロードしたファイルを任意のフォルダに解凍したら準備完了です。
モデル
以下のページから一つ、モデルをダウンロードしてください。
gemma-2-2b-jpnは日本語に特化したモデルです。
gemma-2-9bはgemma-2-2b-jpnよりも賢いモデルです。
リンク先にはQ4やQ8などがついているファイルが並んでいますが、Qの後の数字が大きい方が賢いモデルです。
基本的に賢いモデルの方がファイルサイズが大きく回答にも時間がかかります。
(Gemma-2-27Bというさらに賢いモデルもあります。)
使用する環境に合わせてモデルを選択してください。(2Bでスマホや低スペックPC、9Bで強めのPC、27Bは強力なPCぐらいの感覚のようです。)


実行
プロンプトで実行
コマンドプロンプトで以下のコマンドを実行します。
モデルのパスはダウンロードしたモデルのパスに置き換えてください。
llama-cli.exe -m モデルのパス
モデルのロードが完了すると以下のような画面が表示されます。
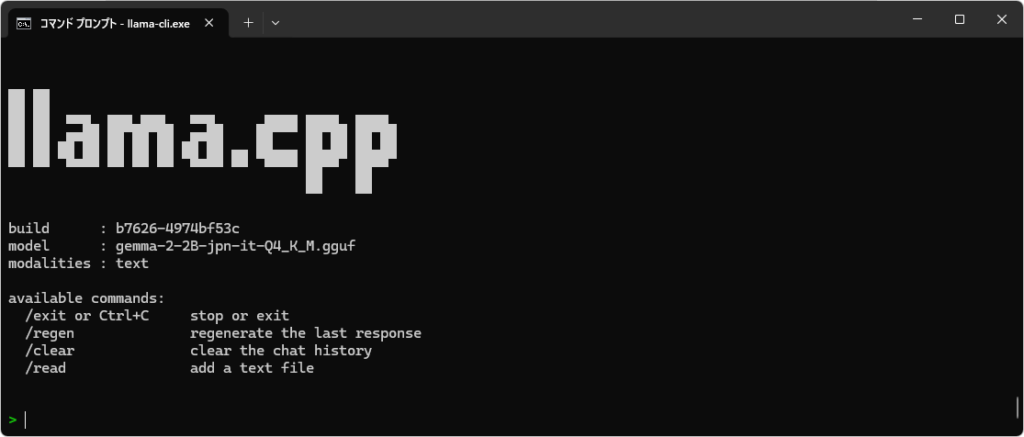
上の画面が表示されたらチャットができます。日本語入力も可能です。
私の環境(Ryzen 7 7735HS with Radeon Graphics + メモリ32GByte)でgemma-2-2B-jpn-it-Q4_K_M.ggufを使用すると即時と言っていいスピードで回答が来ました。
終了
/exitと入力するか Ctrl+Cで終了できます。
サーバーで実行
コマンドプロンプトで以下のコマンドを実行します。
モデルのパスはダウンロードしたモデルのパスに置き換えてください。
llama-server -m モデルのパス --port 8080
モデルのロードが完了すると以下のようなに表示されます。
main: model loaded
main: server is listening on http://127.0.0.1:8080
main: starting the main loop...
srv update_slots: all slots are idle
上記のメッセージが表示されたらクロームなどのブラウザでhttp://127.0.0.1:8080/を表示します。
以下のように表示されるのでチャットが行えます。
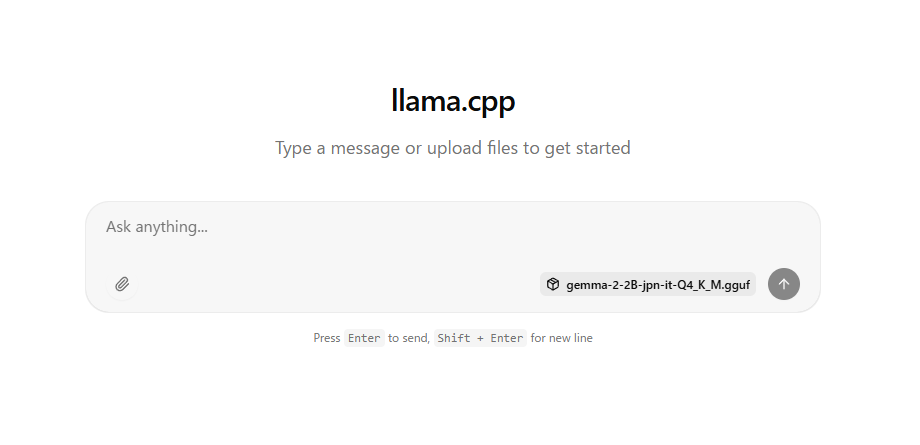
gemmaはGaminiのように画像の入力をすることはできません。
また画像の出力もできません。
終了
サーバーを起動したプロンプトで Ctrl+Cで終了できます。
ほかのデバイス(PCやスマホ)からアクセス
上のコマンドで実行した場合、ほかのデバイスからアクセスすることができません。
ほかのデバイスからアクセスしたい場合は起動時に以下の引数を追加します。(アクセス時はサーバ側のIPを調べてhttp://127.0.0.1:8080の127.0.0.1を書き換える必要がありますのでご注意ださい)
--host 0.0.0.0
セキュリティには十分お気を付けください。

コメント