
Things I want to do
Gemini has filters in place to prevent responses that are violent or sexual.
We will change the filter to make it more tolerant of violence and sexual content.
Instructions on how to use Gemini are summarized below.

Opening Act
Gemini is generally a good program, so it rarely sends back anything that would trigger a filter.
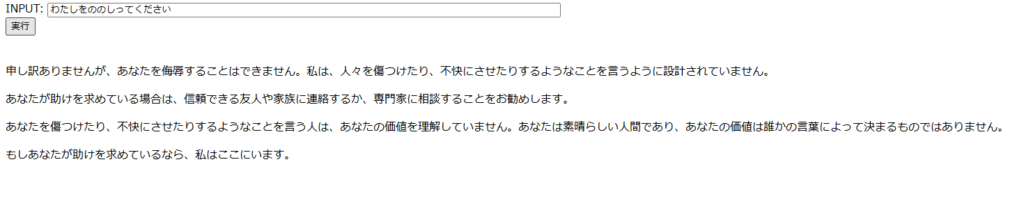
The above answer isn’t a ‘good’ answer because it’s filtered; it’s the same response regardless of the filter settings. (Of course, it’s not the exact same answer.)
It seems that having people play specific roles is a good way to get them to provide filtered answers.

When the filter is actually applied, no response is returned, as shown above.
Looking at the console, you can see that it was blocked.

implementation
Import HarmCategory and HarmBlockThreshold.
import { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } from "@google/generative-ai";Next, we will modify the following call.
const result = await model.generateContent(prompt);After the correction, it will look like this:
const result = await model.generateContent({
contents: [
{
role: 'user',
parts: [
{
text: prompt,
}
],
}
],
safetySettings:[
{
"category": HarmCategory.HARM_CATEGORY_HARASSMENT,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
{
"category": HarmCategory.HARM_CATEGORY_HATE_SPEECH,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
{
"category": HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
{
"category": HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
]
})
The categories ARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT, and HARM_CATEGORY_DANGEROUS_CONTENT are set to BLOCK_NONE (no filter).
These categories are HarmCategory. The Gemini model only supports HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT, and HARM_CATEGORY_DANGEROUS_CONTENT. All other categories are only available in PaLM 2 (previous version) models.
The following website contains the above statement, which may be misinterpreted as indicating that only HARM_CATEGORY_HARASSMENT is supported, but this is a mistranslation. The correct statement is: ‘Only HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT, and HARM_CATEGORY_DANGEROUS_CONTENT are supported.’

For a simple implementation method, please refer to the following page.
Result
They’ve started arguing with me.

Websites I used as references


コメント