
Coisas que eu quero fazer
Executaremos o LLM (inteligência artificial para bate-papo) localmente com entrada de imagem usando o arquivo llama.cpp.
Este artigo utiliza o Qwen2.5-VL, o modelo local do Google.
Ele pode ser executado em GPUs AMD, bem como em sistemas sem GPU (CPU).
Consulte a página seguinte para obter instruções sobre como iniciar o Gamma.

configuração do ambiente
lhama.cpp
Faça o download do arquivo Zip apropriado para o seu ambiente na página seguinte.
Se você quiser executá-lo no Windows com uma GPU AMD (ou em um sistema sem GPU), pode usar o pacote Vulkan.
Ao usar uma GPU Nvidia, funcionará com o pacote CUDA.
Se não funcionar com a versão acima, use o pacote otimizado para CPU.
Depois de extrair o arquivo baixado para uma pasta de sua escolha, você estará pronto para começar.
Modelo
Baixe dois arquivos das seguintes páginas: um de Qwen2.5-VL-3B-Instruct-XXXXXXX.gguf e outro de mmproj-Qwen2.5-VL-3B-Instruct-XXXXXXX.gguf.

execução
Executar no servidor
Execute o seguinte comando no prompt de comando.
Caminho do modeloSubstitua pelo caminho para o modelo baixado.
llama-server -m Caminho do modelo --mmproj Trajetória do modelo mmproj --porta 8080
Após o carregamento completo do modelo, ele será exibido da seguinte forma:
principal: modelo carregado
principal: o servidor está escutando em http://127.0.0.1:8080
principal: iniciando o loop principal...
srv update_slots: todos os slots estão ociosos
Caso a mensagem acima seja exibida, abra http://127.0.0.1:8080/ em um navegador como o Chrome.
A seguinte mensagem será exibida, permitindo que você converse com outras pessoas.
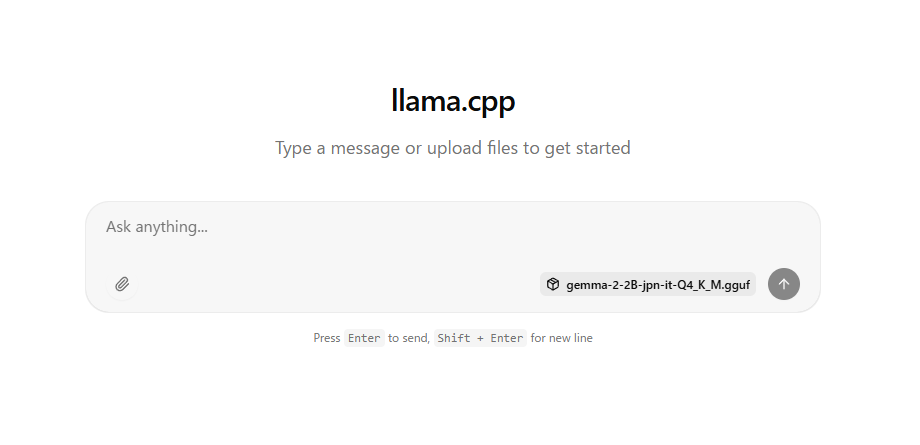
Você pode arrastar e soltar arquivos de imagem na página.
solução de problemas
Ao inserir uma imagem, apareceu um relatório de erro da AMD e o programa travou.
Resolvi o problema fazendo as duas coisas a seguir. ( Não tenho certeza de qual delas causou o problema.)
1. Atualize o driver na página seguinte.

2. Inicie o software AMD (Adrenalin Edition) Altere a configuração do Otimizador de Memória na guia Desempenho → Ajustes para Jogos . (Isso aumentou o uso de memória da GPU de 2 GB para 4 GB.)
Sites que utilizei como referência

コメント