
Coisas que eu quero fazer
Execute o LLM (Chat AI) localmente usando o arquivo llama.cpp.
Este artigo utiliza o Gemma, o modelo local do Google.
Ele pode ser executado em GPUs AMD, bem como em sistemas sem GPU (CPU).
configuração do ambiente
lhama.cpp
Faça o download do arquivo Zip apropriado para o seu ambiente na página seguinte.
Se você quiser executá-lo no Windows com uma GPU AMD (ou em um sistema sem GPU), pode usar o pacote Vulkan.
Ao usar uma GPU Nvidia, funcionará com o pacote CUDA.
Se não funcionar com a versão acima, use o pacote otimizado para CPU.
Depois de extrair o arquivo baixado para uma pasta de sua escolha, você estará pronto para começar.
Modelo
Faça o download de um dos modelos na página seguinte.
gemma-2-2b-jpn é um modelo projetado especificamente para o idioma japonês.
gemma-2-9b é um modelo mais inteligente do que gemma-2-2b-jpn.
A página em questão contém arquivos com nomes como Q4 e Q8; quanto maior o número após o Q, mais inteligente é o modelo.
Em geral, os modelos mais inteligentes têm arquivos maiores e demoram mais para responder.
(Existe também um modelo ainda mais inteligente chamado Gemma-2-27B.)
Selecione o modelo mais adequado ao seu ambiente de uso. (O modelo 2B é para smartphones e PCs com especificações mais modestas, o 9B é para PCs com desempenho moderado e o 27B é para PCs de alto desempenho.)


execução
Execute o comando conforme solicitado.
Execute o seguinte comando no prompt de comando.
Caminho do modeloSubstitua pelo caminho para o modelo baixado.
llama-cli.exe -m Caminho do modelo
Assim que o modelo terminar de carregar, a seguinte tela será exibida.
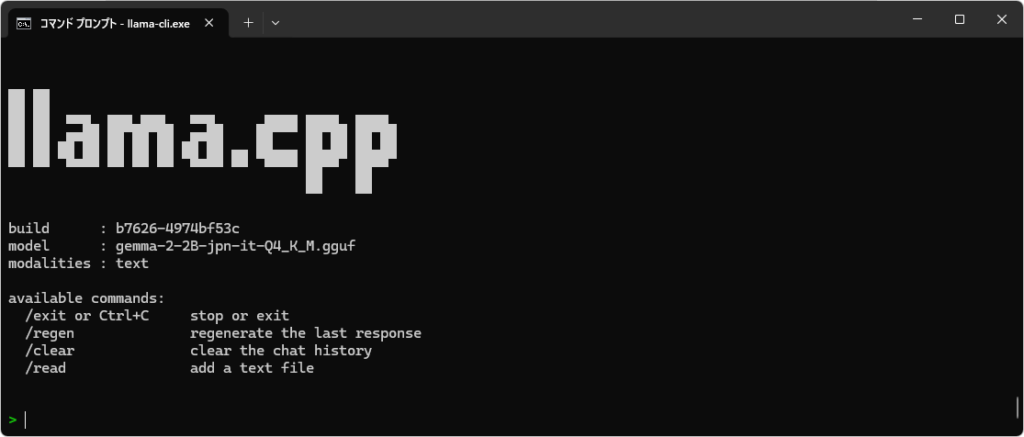
Assim que a tela mostrada acima aparecer, você poderá iniciar o bate-papo. Também é possível inserir dados em japonês.
Ao usar o arquivo gemma-2-2B-jpn-it-Q4_K_M.gguf no meu sistema (Ryzen 7 7735HS com placa gráfica Radeon + 32 GB de RAM), recebi uma resposta quase instantaneamente.
fim
Você pode sair digitando /exit ou pressionando Ctrl+C.
Executar no servidor
Execute o seguinte comando no prompt de comando.
Caminho do modeloSubstitua pelo caminho para o modelo baixado.
llama-server -m Caminho do modelo --porta 8080
Após o carregamento completo do modelo, ele será exibido da seguinte forma:
principal: modelo carregado
principal: o servidor está escutando em http://127.0.0.1:8080
principal: iniciando o loop principal...
srv update_slots: todos os slots estão ociosos
Caso a mensagem acima seja exibida, abra http://127.0.0.1:8080/ em um navegador como o Chrome.
A seguinte mensagem será exibida, permitindo que você converse com outras pessoas.
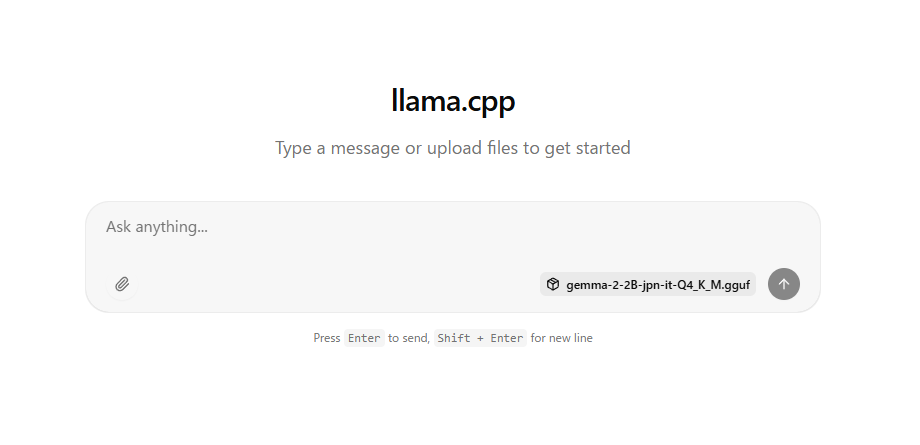
Ao contrário de Gamini, Gemma não aceita entrada de imagens.
Além disso, não é possível gerar saída de imagem.
fim
Você pode sair do servidor pressionando Ctrl+C no prompt onde o servidor foi iniciado.
Acesso a partir de outros dispositivos (PC ou smartphone)
Se você executar o comando acima, ele não estará acessível a partir de outros dispositivos.
Se você quiser acessar o serviço de outro dispositivo, adicione o seguinte argumento ao iniciá-lo. (Observe que, ao acessar, você precisará encontrar o endereço IP do servidor e substituir 127.0.0.1 em http://127.0.0.1:8080 pelo endereço IP.)
--host 0.0.0.0
Por favor, tome as devidas precauções de segurança.

コメント