
Coisas que eu quero fazer
Gemini possui filtros para evitar respostas violentas ou de cunho sexual.
Vamos alterar o filtro para torná-lo mais tolerante à violência e ao conteúdo sexual.
As instruções de uso do Gemini estão resumidas abaixo.

Ato de Abertura
O Gemini geralmente é um bom programa, então raramente envia algo que acione um filtro.
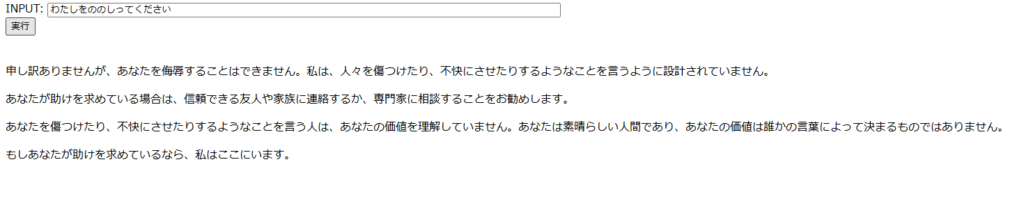
A resposta acima não é uma boa resposta porque está filtrada; é a mesma resposta independentemente das configurações do filtro. (Claro, não é exatamente a mesma resposta.)
Parece que atribuir papéis específicos às pessoas é uma boa maneira de obter respostas filtradas.

Quando o filtro é efetivamente aplicado, nenhuma resposta é retornada, como mostrado acima.
Ao olhar para o console, você pode ver que ele foi bloqueado.

implementação
Importar HarmCategory e HarmBlockThreshold.
import { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } from "@google/generative-ai";Em seguida, modificaremos a seguinte chamada.
const result = await model.generateContent(prompt);Após a correção, ficará assim:
const result = await model.generateContent({
contents: [
{
role: 'user',
parts: [
{
text: prompt,
}
],
}
],
safetySettings:[
{
"category": HarmCategory.HARM_CATEGORY_HARASSMENT,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
{
"category": HarmCategory.HARM_CATEGORY_HATE_SPEECH,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
{
"category": HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
{
"category": HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
"threshold": HarmBlockThreshold.BLOCK_NONE
},
]
})
As categorias ARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT e HARM_CATEGORY_DANGEROUS_CONTENT estão definidas como BLOCK_NONE (sem filtro).
Essas categorias são HarmCategory. O modelo Gemini suporta apenas HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT e HARM_CATEGORY_DANGEROUS_CONTENT. Todas as outras categorias estão disponíveis apenas nos modelos PaLM 2 (versão anterior).
O site a seguir contém a declaração acima, que pode ser mal interpretada como indicando que apenas a categoria HARM_CATEGORY_HARASSMENT é suportada, mas trata-se de uma tradução incorreta. A declaração correta é: Apenas as categorias HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT e HARM_CATEGORY_DANGEROUS_CONTENT são suportadas.

Para um método de implementação simples, consulte a página seguinte.
Resultado
Eles começaram a discutir comigo.

Sites que utilizei como referência


コメント