
Things I want to do
Let’s try running LLM using an AMD GPU.
We will use DirectML and sample code for DirectML.
We will be making code modifications. Please proceed at your own risk.
However, it barely works (unstable, produces strange answers) in the following environments.
| CPU | AMD Ryzen 7 7735HS |
|---|---|
| memory | 32GB |
| storage | External HDD (The system disk is an SSD, and due to its large capacity, it is used externally.) |
| GPU | AMD Radeon 680M (Built-in CPU) |
Environment setup
Create a working folder.
Clone the following repository.
Move to venv environment (optional)
If necessary, run the following command in the command prompt to create and activate the Venv environment.
python -mvenv venv
venv\scripts\activate.batMove to working folder
Execute the following command to access the LLM sample code. (The cloned repository is a collection of DirectML sample code, so you will need to navigate to a working folder to use individual samples.)
cd PyTorch\llmLibrary Installation
Execute the following command to install the necessary libraries.
pip install -r requirements.txt
pip install torch_directml
pip install huggingface_hubCode modification
Delete or comment out the following lines.
from huggingface_hub.utils._errors import RepositoryNotFoundErrorEdit it as follows, or delete the except block.
Before:
except RepositoryNotFoundError as e:after:
except:An error has occurred due to the update of huggingface_hub.
The system is running by disabling the parts that are causing the errors.
There’s a possibility that the model download error handling isn’t working correctly.
boot
Execute the following command. (The model will be downloaded automatically, so the first time it runs, it will take some time.)
python app.pyIf the following appears in the command prompt, open the displayed URL in your browser.
Running on local URL: http://127.0.0.1:7860If you see a screen like the one below, it was successful.
(Enter a prompt at the bottom of the screen, and the answer will appear at the top.)
Result
I was able to run LLM on an AMD CPU’s integrated GPU.
The response speed is also reasonable. (It might even be faster than Gemeini, etc.)
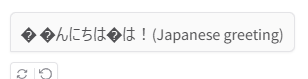
However, I tried two models, but neither worked properly, as shown below.
(I don’t think they give the exact same answer, so I think it’s a matter of the model or specifications.)
microsoft/Phi-3-mini-4k-instruct(Initial value)- No matter what I ask, I only get the same answer (though it’s not exactly the same, so it seems to be working).
microsoft/phi-2- After several exchanges, an error occurs.
- Garbled characters in Japanese

コメント