
やりたいこと
AMDのGPUを使用してでLLMを動作させてみます。
DirectMLとDirectMLのサンプルコードを使用します。
コードの修正を行います。実行は自己責任でお願いします。
ただし以下の環境でギリギリ動作する(不安定、回答が変)状態です。
| CPU | AMD Ryzen 7 7735HS |
|---|---|
| メモリ | 32GB |
| ストレージ | 外付けHDD (システムディスクはSSD、容量が大きいため外付けで運用) |
| GPU | AMD Radeon 680M (CPU内臓) |
環境構築
作業用のフォルダを作成します。
以下のリポジトリをクローンします。
venv環境への移動(任意)
必要であればコマンドプロンプトで以下のコマンドを実行して、Venvの環境を作成してアクティブにします。
python -mvenv venv
venv\scripts\activate.bat作業フォルダへ移動
以下のコマンドを実行してLLMのサンプルコードに移動します。(クローンしたリポジトリはDirectMLのサンプルコードの集まりのため個々のサンプルを使用するには作業フォルダに移動します。)
cd PyTorch\llmライブラリのインストール
以下のコマンドを実行して必要なライブラリのインストールを行います。
pip install -r requirements.txt
pip install torch_directml
pip install huggingface_hubコード修正
以下の行を削除するかコメントアウトします。
from huggingface_hub.utils._errors import RepositoryNotFoundError以下のように編集するかexceptブロックを削除します。
Before:
except RepositoryNotFoundError as e:after:
except:huggingface_hubのバージョンアップによりエラーが出るようになっています。
エラーが出る箇所を無効化することで動作させています。
モデルのダウンロードのエラー処理が正しく行えていない可能性がります。
起動
以下のコマンド起動します。(モデルが自動でダウンロードされるため、初回は時間がかかります。)
python app.pyコマンドプロンプトに以下のように表示されたら表示されているURLをブラウザで表示します。
Running on local URL: http://127.0.0.1:7860以下のような画面が表示されれば成功です。
(画面下にプロンプトを入力すると上側に回答が表示されます。)
結果
AMDのCPU内臓GPUでLLMを動作させることができました。
回答の速度も現実的です。(Gemeiniなどよりも早いかもしれないです。)
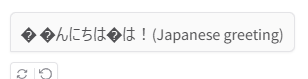
ただし2つのモデルを試したのですが以下のようにまともに動作しませんでした。
(全く同じ回答をするわけではないのでモデルかスペックの問題だと思っています。)
microsoft/Phi-3-mini-4k-instruct(初期値)- 何を聞いても同じような回答しかしない(全く同じではないので動作はしていそう)
microsoft/phi-2- 何度かやり取りするとエラーになる
- 日本語で文字化け

コメント