
我想做的事情
我们将使用 llama.cpp 在本地运行 LLM(聊天 AI),并以图像作为输入。
本文使用了谷歌的本地模型 Qwen2.5-VL。
它既可以在 AMD GPU 上运行,也可以在没有 GPU(CPU)的系统上运行。
请参考下一页,了解如何启动 Gamma。

环境设置
llama.cpp
请从以下页面下载适合您环境的 Zip 文件。
如果你想在配备 AMD GPU 的 Windows 系统(或没有 GPU 的系统)上运行它,可以使用 Vulkan 软件包。
使用Nvidia GPU时,它将与CUDA软件包配合使用。
如果上述版本不起作用,请使用 CPU 优化版软件包。
Releases · ggml-org/llama.cpp
LLM inference in C/C++. Contribute to ggml-org/llama.cpp development by creating an account on GitHub.
github.com
将下载的文件解压到你选择的文件夹后,就可以开始了。
模型
从以下页面下载两个文件:一个来自 Qwen2.5-VL-3B-Instruct-XXXXXXX.gguf,另一个来自 mmproj-Qwen2.5-VL-3B-Instruct-XXXXXXX.gguf。

ggml-org/Qwen2.5-VL-3B-Instruct-GGUF at main
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
执行
在服务器上运行
在命令提示符中执行以下命令。
模型路径替换为已下载模型的路径。
llama-server -m 模型路径 --mmproj mmproj模型的路径 --端口 8080
模型加载完成后,将显示如下:
主要:模型已加载
主服务器正在监听 http://127.0.0.1:8080
主循环:开始主循环……
srv update_slots:所有槽位均处于空闲状态
如果出现上述消息,请在 Chrome 等浏览器中打开 http://127.0.0.1:8080/。
将显示以下内容,您可以进行聊天。
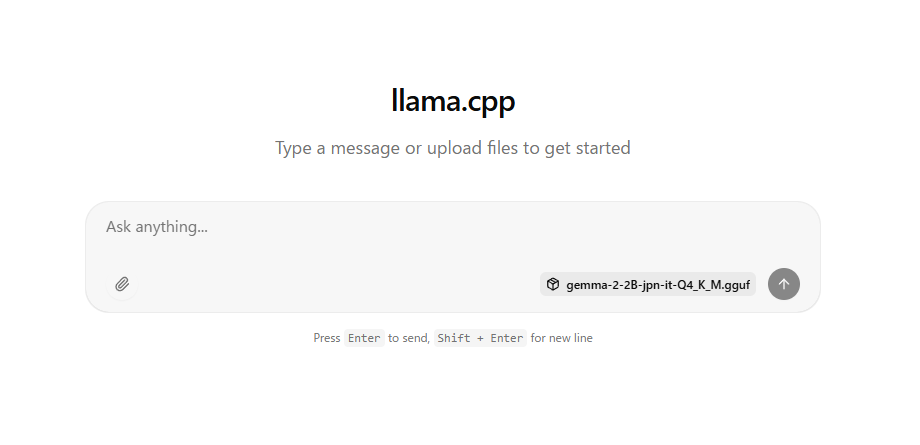
您可以将图像文件拖放到页面上。
故障排除
当我输入图片时,出现了 AMD 错误报告,程序崩溃了。
我通过以下两件事解决了这个问题。(我不确定是哪件事起了作用。)
1. 从以下页面更新驱动程序。

プロセッサ/グラフィックスのドライバーとサポート
AMD 製品のドライバーとソフトウェアをダウンロード — Windows および Linux のサポート、自動検出ツール、インストールの詳細ガイドもご利用いただけます。
www.amd.com
2. 启动 AMD 软件(Adrenalin 版) 在“性能” → “调优”选项卡中,将内存优化器设置更改为“游戏” 。(这会将GPU的内存使用量从2GB增加到4GB。)
我用作参考的网站

【備忘録】llama.cppで、マルチモーダルがサポートされたので使ってみた。|猫又
個人用の備忘録です。 llama.cppは以下を使用 ・llama-b5342-bin-win-cuda12.4-x64 モデルは以下からダウンロードして使用 ・Qwen2.5-VL-3B-Instruct-Q4_K_M.gguf ・mmproj-Qwen2.5-VL-3B-Instruct-f16...
note.com
コメント