
我想做的事情
使用 llama.cpp 在本地运行 LLM(聊天 AI)。
本文使用了谷歌的本地模型 gemma。
它既可以在 AMD GPU 上运行,也可以在没有 GPU(CPU)的系统上运行。
环境设置
llama.cpp
请从以下页面下载适合您环境的 Zip 文件。
如果你想在配备 AMD GPU 的 Windows 系统(或没有 GPU 的系统)上运行它,可以使用 Vulkan 软件包。
使用Nvidia GPU时,它将与CUDA软件包配合使用。
如果上述版本不起作用,请使用 CPU 优化版软件包。
将下载的文件解压到你选择的文件夹后,就可以开始了。
模型
请从以下页面下载其中一个模型。
gemma-2-2b-jpn 是专为日语设计的模型。
gemma-2-9b 比 gemma-2-2b-jpn 更智能。
链接页面包含名称类似于 Q4 和 Q8 的文件;Q 后面的数字越大,模型就越智能。
一般来说,更智能的模型文件更大,响应时间更长。
(还有一款更智能的型号,叫做Gemma-2-27B。)
请根据您的使用环境选择合适的型号。(2B 适用于智能手机和低配置电脑,9B 适用于中等配置电脑,27B 适用于高端电脑。)


执行
在提示符处运行
在命令提示符中执行以下命令。
模型路径替换为已下载模型的路径。
llama-cli.exe -m 模型路径
模型加载完成后,将显示以下屏幕。
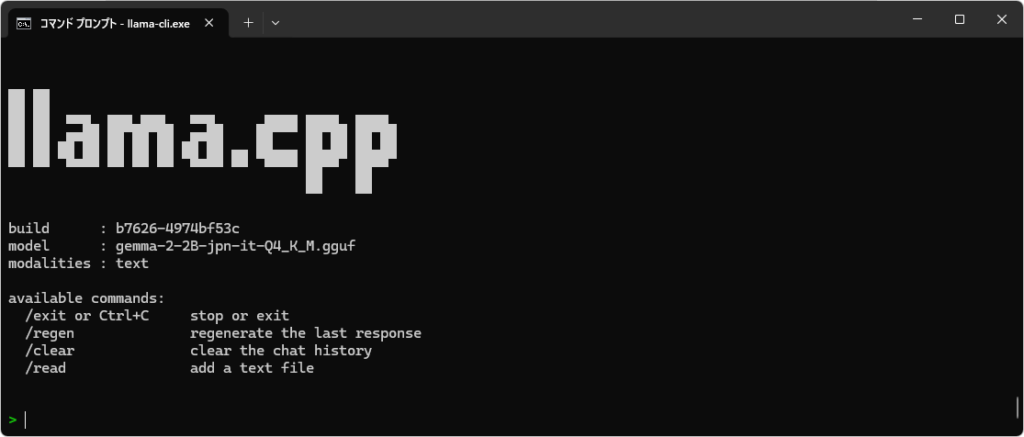
出现上述屏幕后,即可开始聊天。也支持日语输入。
在我的系统(Ryzen 7 7735HS with Radeon Graphics + 32GB RAM)上使用 gemma-2-2B-jpn-it-Q4_K_M.gguf 时,我几乎立即收到了响应。
结尾
你可以输入 /exit 或按 Ctrl+C 退出。
在服务器上运行
在命令提示符中执行以下命令。
模型路径替换为已下载模型的路径。
llama-server -m 模型路径 --端口 8080
模型加载完成后,将显示如下:
主要:模型已加载
主服务器正在监听 http://127.0.0.1:8080
主循环:开始主循环……
srv update_slots:所有槽位均处于空闲状态
如果出现上述消息,请在 Chrome 等浏览器中打开 http://127.0.0.1:8080/。
将显示以下内容,您可以进行聊天。
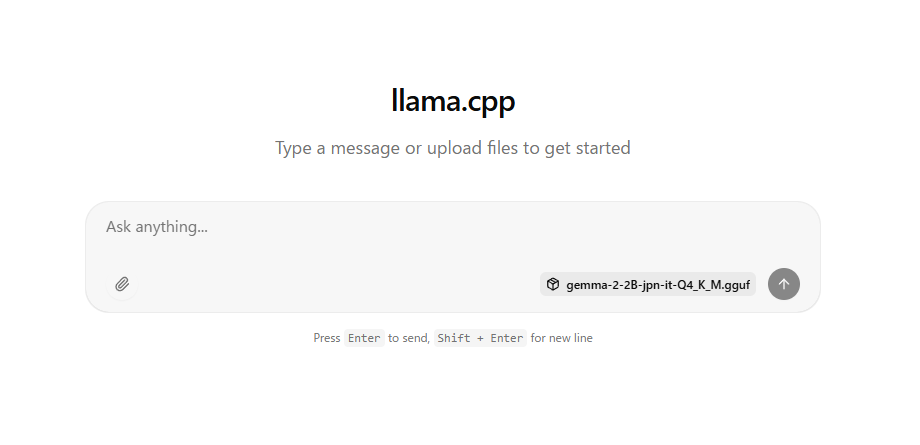
与 Gamini 不同,Gemma 不能接受图像输入。
此外,无法输出图像。
结尾
您可以在启动服务器的提示符处按 Ctrl+C 退出服务器。
通过其他设备(电脑或智能手机)访问
如果执行上述命令,则其他设备将无法访问该内容。
如果您想从其他设备访问它,请在启动时添加以下参数。(请注意,访问时您需要找到服务器的 IP 地址,并将 http://127.0.0.1:8080 中的 127.0.0.1 替换为服务器的 IP 地址。)
--host 0.0.0.0
请采取充分的安全防范措施。

コメント