
Coisas que eu quero fazer
Vamos tentar executar o LLM usando uma GPU AMD.
Usaremos DirectML e um código de exemplo para DirectML.
Faremos alterações no código. Prossiga por sua conta e risco.
No entanto, funciona muito mal (instável, produz respostas estranhas) nos seguintes ambientes.
| CPU | AMD Ryzen 7 7735HS |
|---|---|
| memória | 32 GB |
| armazenar | Disco rígido externo (O disco do sistema é um SSD e, devido à sua grande capacidade, é usado externamente.) |
| GPU | AMD Radeon 680M (CPU integrada) |
Configuração do ambiente
Crie uma pasta de trabalho.
Clone o seguinte repositório.
Mudar para o ambiente venv (opcional)
Se necessário, execute o seguinte comando no prompt de comando para criar e ativar o ambiente Venv.
python -mvenv venv
venv\scripts\activate.batMover para a pasta de trabalho
Execute o seguinte comando para acessar o código de exemplo do LLM. (O repositório clonado é uma coleção de códigos de exemplo do DirectML, portanto, você precisará navegar até uma pasta de trabalho para usar exemplos individuais.)
cd PyTorch\llmInstalação da Biblioteca
Execute o seguinte comando para instalar as bibliotecas necessárias.
pip install -r requirements.txt
pip install torch_directml
pip install huggingface_hubModificação de código
Apague ou comente as seguintes linhas.
from huggingface_hub.utils._errors import RepositoryNotFoundErrorEdite da seguinte forma ou exclua o bloco ‘exceto’.
Antes:
except RepositoryNotFoundError as e:depois:
except:Ocorreu um erro devido à atualização do embraceface_hub.
O sistema está funcionando desativando as partes que estão causando os erros.
Existe a possibilidade de o tratamento de erros no download do modelo não estar funcionando corretamente.
bota
Execute o seguinte comando. (O modelo será baixado automaticamente, portanto, na primeira execução, levará algum tempo.)
python app.pySe a seguinte mensagem aparecer na linha de comando, abra o URL exibido no seu navegador.
Running on local URL: http://127.0.0.1:7860Se você vir uma tela como a abaixo, significa que a operação foi bem-sucedida.
(Digite uma pergunta na parte inferior da tela e a resposta aparecerá na parte superior.)
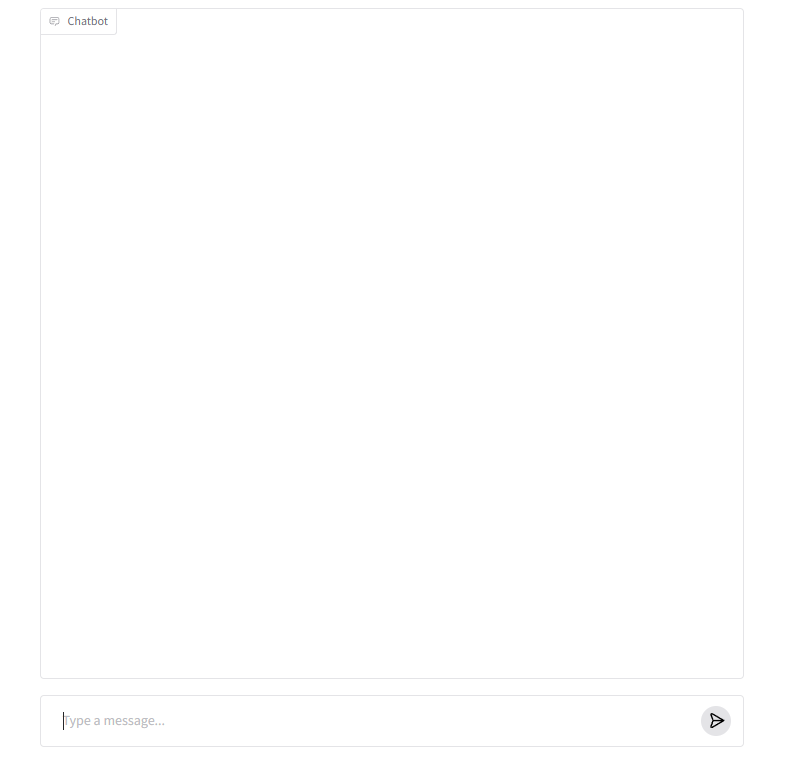
Resultado
Consegui executar o LLM na GPU integrada de uma CPU AMD.
A velocidade de resposta também é razoável. (Pode até ser mais rápida que a do Gemini, etc.)
No entanto, experimentei dois modelos, mas nenhum funcionou corretamente, como mostrado abaixo.
(Não creio que deem exatamente a mesma resposta, então acho que é uma questão de modelo ou especificações.)
microsoft/Phi-3-mini-4k-instruct(Valor inicial)- Não importa o que eu pergunte, sempre recebo a mesma resposta (embora não seja exatamente a mesma, então parece que está funcionando).
microsoft/phi-2- Após várias trocas de mensagens, ocorre um erro.
- Caracteres ilegíveis em japonês
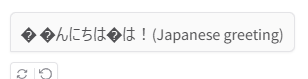

コメント