
やりたいこと
stable-diffusion.cppを使用してコマンドラインからQwen-Imageを実行します。
AMDのGPUでもCPUでも実行可能です。
環境構築
stable-diffusion.cpp
以下のページから自分の環境にあったZipファイルをダウンロードします。
AMDのGPUで動かしたい場合はvulkanとつくものかrocmとつくものです。
(基本的にはvulkanでいいと思います。rocmはどうするGPUが限られるはずです。)
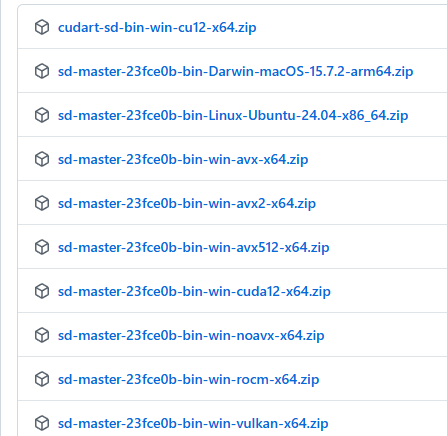
NVidiaのGPUはcudaが付くものが対象です。
avx512,avx2,avx,noavxはCPU動作です。お使いのCPUで使用できるavxのバージョンを調べてダウンロードしてください。(私は誤解していたのですがAMDのCPUもAVX使えるようです。どのバージョンが使用できるかはAIに聞いちゃうのが楽です。)
対象のダウンロードしたファイルを任意のフォルダに解凍したら準備完了です。
モデル
以下のページから一つづつ、計3つのモデルをダウンロードしてください。
複数ファイルがあるものに関しては、ファイルサイズが大きいほどメモリが必要で精度がいいです。
環境と相談の上、どのモデルを使用するか決めてください。
私の環境(Ryzen 7 7735HS with Radeon Graphics + メモリ32G)だとQwen_Image-Q8_0.ggufは動作しなかったためQwen_Image-Q4_K_S.ggufを使用しました。
diffusion-model

vae

llm

実行
コマンドラインを起動してstable-diffusion.cppを解凍したフォルダに移動します。
以下のコマンドを実行します。(モデルパス部分は使用するmodelのパスに置き換えてください)
sd-cli.exe --diffusion-model Diffusionモデルパス --vae VAEモデルパス --llm llmモデルパス -p "a cat" --cfg-scale 2.5 --sampling-method euler -v --offload-to-cpu -H 512 -W 512 --diffusion-fa --flow-shift 3
./output.pngに猫の画像が生成されれば成功です。

公式の例では-p ‘a cat’ のようにプロンプトを’で囲っていますがこれでは動作しません。”で囲ってください。
オプション(引数)
オプションは以下のページにまとめられています。
よく使われる基本的なものだけ以下に記載します。
| -m | モデルのパス |
| -p | プロンプト |
| -s | シード値 ランダムで生成するには-1を指定する。 指定しない場合、毎回同じ画像が生成されるため注意。 |
-H | 画像高さ |
| -W | 画像幅 |
--vae | VAEのパス |
--steps | ステップ。初期値20 モデルによっては少ない数字の方がいいので注意。 (Qwen Imageの公式の例では50でした。) |
実行速度
画像の生成速度は以下の通りです。(モデルのロード時間やイテレーション後の時間は含んでいません)
| モデル | 生成時間(s) |
| stable-diffusion(Vulkan) | 36 |
| Qwen Image(Vulkan) | 623 |
StableDiffusionと比べるとだいぶ遅いです。
エラー
以下のエラーが出るときはメモリが足りていません。使用するモデルを変更するなり、他のアプリを終了すると動作する可能性があります。
[ERROR] ggml_extend.hpp:83 - alloc_tensor_range: failed to allocate Vulkan0 buffer of size 1043908608
[ERROR] ggml_extend.hpp:1774 - qwen_image alloc runtime params backend buffer failed, num_tensors = 1933
[ERROR] ggml_extend.hpp:1955 - qwen_image offload params to runtime backend failed
[ERROR] stable-diffusion.cpp:1727 - diffusion model compute failed
[ERROR] stable-diffusion.cpp:1861 - Diffusion model sampling failed
[ERROR] stable-diffusion.cpp:3112 - sampling for image 1/1 failed after 5.14s

コメント